Nguồn gốc của công nghệ Text to Speech (TTS)
Ý tưởng về việc tạo ra máy móc có thể mô phỏng giọng nói con người đã được khơi nguồn từ hơn 200 năm trước. Vào năm 1779, Giáo sư người Nga Christian Kratzenstein đã chế tạo một thiết bị có khả năng tái tạo các nguyên âm nhân tạo. Tiếp nối đó, năm 1791, Wolfgang Von Kempelen đã giới thiệu “Acoustic-Mechanical Speech Machine” – một thiết bị có thể tạo ra các âm thanh đơn lẻ và một số tổ hợp âm thanh, đánh dấu bước tiến đầu tiên trong việc tổng hợp giọng nói.

Wolfgang Von Kempelen đã sáng tạo ra Acoustic-Mechanical Speech Machine
Đến đầu thế kỷ 19, Charles Wheatstone đã cải tiến và chế tạo thành công một phiên bản “máy nói” dựa trên thiết kế của Von Kempelen. Thiết bị này phức tạp hơn, có khả năng tạo ra các nguyên âm, phụ âm và thậm chí cả các từ hoàn chỉnh. Đây được xem là một bước đột phá, đặt nền móng cho các nghiên cứu về công nghệ chuyển văn bản thành giọng nói sau này.
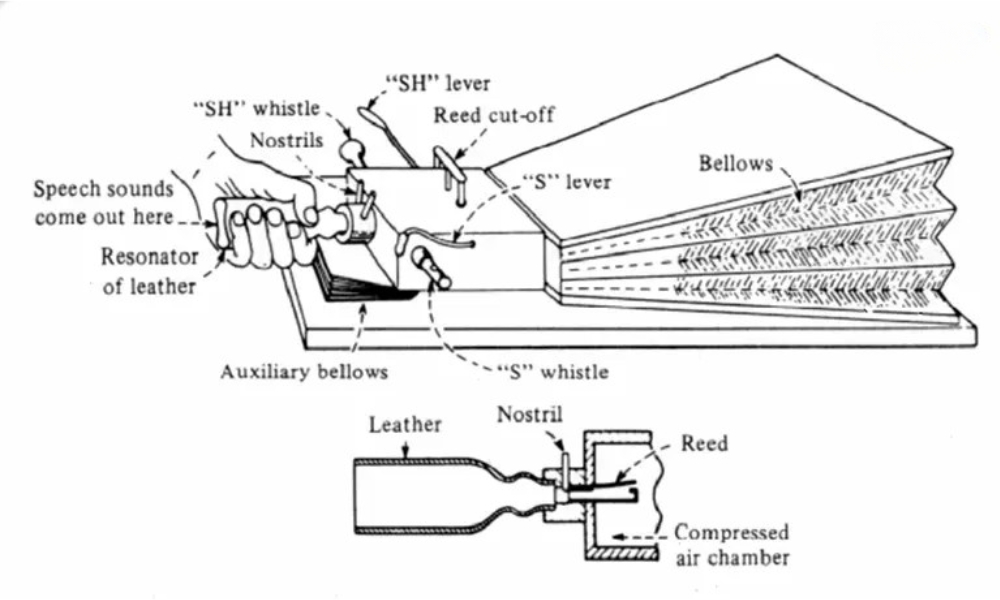
Charles Wheatstone đã cải tiến và chế tạo thành công một phiên bản “máy nói”
Vào năm 1937 – 1938, tại Bell Labs, Homer Dudley đã phát triển thành công thiết bị tổng hợp giọng nói VODER, dựa trên công trình về bộ phát âm của mình. VODER không chỉ tạo ra các âm thanh mà còn có khả năng mô phỏng giọng nói người một cách rõ ràng hơn. Khi được trưng bày tại Hội chợ Thế giới New York năm 1939, VODER đã thu hút sự chú ý lớn, mở ra tiềm năng ứng dụng rộng rãi cho công nghệ Text to Speech trong tương lai.

Homer Dudley đã thành công chế tạo ra thiết bị tổng hợp giọng nói VODER
Lịch sử hình thành và phát triển của công nghệ TTS
Công nghệ chuyển văn bản sang giọng nói (TTS) đã trải qua một hành trình dài từ những thí nghiệm đầu tiên đến các ứng dụng hiện đại, phản ánh sự tiến bộ vượt bậc của khoa học và công nghệ qua từng giai đoạn.
● Giai đoạn bắt đầu (1950 – 1970)
Công nghệ TTS khởi nguồn từ những thập niên 1950 khi hệ thống tổng hợp giọng nói đầu tiên được phát triển. Năm 1961, John Larry Kelly, Jr. và Louis Gerstman tại Bell Labs đã sử dụng máy tính IBM 704 để tổng hợp giọng nói và trình diễn bài hát "Daisy Bell". Đây là bước tiến quan trọng, đánh dấu khả năng máy móc mô phỏng giọng nói con người. Năm 1966, mã hóa dự đoán tuyến tính (LPC) ra đời, đặt nền móng cho việc phân tích và tổng hợp âm thanh trong những thập niên sau.

John Larry Kelly, Jr. và Louis Gerstman tại Bell Labs đã dùng máy tính IBM 704 để tổng hợp giọng nói
● Giai đoạn phát triển (1970 – 2010)
Từ năm 1970, Fumitada Itakura đã phát triển các công nghệ như cặp phổ vạch LSP (Line Spectrum Pair), giúp làm nén dữ liệu giọng nói hiệu quả hơn. Những năm 1975, hệ thống tổng hợp giọng nói MUSA và các thiết bị cầm tay như Speech+ đã hỗ trợ người khiếm thị, cùng với Speak & Spell (1978) của Texas Instruments giúp TTS trở nên phổ biến, rộng rãi hơn.
Vào thập niên 1990, Ann Syrdal tại AT&T Bell Labs đã tạo ra giọng nữ đầu tiên cho máy tổng hợp giọng nói, cải thiện tính tự nhiên và thân thiện. Năm 1999, Microsoft phát hành Narrator - phần mềm đọc màn hình tích hợp trong hệ điều hành Windows, đưa TTS tiếp cận đến hàng triệu người dùng trên toàn cầu.

Speak & Spell (1978) của Texas Instruments giúp TTS trở nên được sử dụng rộng rãi hơn
● Giai đoạn bùng nổ (2010 – nay)
Kể từ năm 2010, trí tuệ nhân tạo (AI) và mạng nơ-ron sâu (DNN) đã thay đổi toàn diện TTS, giúp tạo ra giọng nói tự nhiên, biểu cảm hơn. Những công cụ như WaveNet của DeepMind và Deep Voice 3 của Baidu giúp người dùng có thể sao chép giọng nói chỉ với vài phút dữ liệu âm thanh. TTS ngày nay đã tích hợp sâu vào các trợ lý ảo như Siri, Google Assistant, Alexa, cùng nhiều ứng dụng khác như sách nói, hệ thống thông báo công cộng, trò chơi điện tử.

TTS ngày nay đã tích hợp sâu hơn vào các trợ lý ảo như Siri, Google Assistant, Alexa
Hướng phát triển trong tương lai của công nghệ chuyển văn bản sang giọng nói
Trong tương lai, công nghệ chuyển văn bản sang giọng nói (TTS) hứa hẹn sẽ ngày càng phát triển mạnh mẽ nhờ sự tiến bộ của trí tuệ nhân tạo và học sâu (deep learning). Giọng nói nhân tạo sẽ trở nên tự nhiên hơn, có khả năng tái tạo các sắc thái và ngữ điệu giống hệt giọng nói con người. Các trợ lý ảo và chatbot cũng sẽ tạo ra các cuộc trò chuyện tự nhiên hơn, mang lại cảm giác giao tiếp như với con người. Ngoài ra, công nghệ chuyển đổi văn bản thành phiên âm (text-to-phoneme) cũng sẽ được cải tiến, nâng cao độ chính xác và hiệu quả của các hệ thống nhận dạng giọng nói.
Hơn nữa, TTS cũng sẽ được tích hợp sâu hơn vào đời sống hàng ngày, đặc biệt thông qua các thiết bị thuộc hệ sinh thái Internet vạn vật (IoT). Người dùng sẽ có thể điều khiển thiết bị bằng giọng nói theo thời gian thực, tiện lợi và hiệu quả cao hơn trong sinh hoạt và công việc của con người.
Ứng dụng công nghệ Text to Speech trong các lĩnh vực đời sống
Công nghệ Text to Speech (TTS) là một giải pháp chuyển đổi văn bản thành giọng nói tự động. Công nghệ này có khả năng tạo ra giọng đọc tự nhiên, được ứng dụng trong nhiều lĩnh vực khác nhau trong cuộc sống.
Giáo dục
Trong lĩnh vực giáo dục, TTS đóng vai trò hỗ trợ người học tiếp cận kiến thức dễ dàng hơn:
● Hỗ trợ học sinh khuyết tật: Công nghệ TTS giúp học sinh khiếm thị hoặc mắc chứng khó đọc tiếp cận tài liệu học tập một cách thuận tiện. TTS có thể đọc sách giáo khoa, bài giảng hoặc ghi chú học tập, giúp các em theo kịp chương trình học.
● Tạo sách nói: TTS được sử dụng để sản xuất sách nói nhanh chóng và chi phí thấp. Điều này giúp người học có thể tiếp thu kiến thức ngay cả khi đang di chuyển hoặc không có thời gian đọc sách.
● Học ngoại ngữ: TTS có giọng đọc chuẩn, hỗ trợ người học cải thiện kỹ năng nghe và phát âm trong các ngôn ngữ khác nhau.

TTS đóng vai trò hỗ trợ người học tiếp cận kiến thức một cách dễ dàng
Doanh nghiệp
Trong môi trường kinh doanh, TTS giúp doanh nghiệp tự động hóa quy trình và cải thiện dịch vụ:
● Hệ thống trả lời tự động (IVR): TTS được sử dụng trong các tổng đài chăm sóc khách hàng để trả lời các câu hỏi cơ bản, hướng dẫn khách hàng hoặc thông báo thông tin. Từ đó giúp doanh nghiệp duy trì tương tác với khách hàng suốt 24/7.
● Tạo nội dung quảng cáo: Các doanh nghiệp sử dụng TTS để sản xuất nội dung quảng cáo với giọng đọc chuẩn, đồng nhất và có thể dễ dàng chuyển đổi sang nhiều ngôn ngữ khác nhau.
● Cải thiện trải nghiệm khách hàng: TTS giúp cá nhân hóa các dịch vụ, mang lại cảm giác thân thiện hơn khi tương tác với khách hàng.

TTS được ứng dụng trong hệ thống trả lời tự động (IVR) để khâu chăm sóc khách hàng hiệu quả
Y tế
Công nghệ TTS trong lĩnh vực y tế mang lại nhiều lợi ích như:
● Hỗ trợ bệnh nhân khiếm thị: TTS có thể đọc các tài liệu y tế, hướng dẫn sử dụng thuốc hoặc thông báo lịch trình điều trị, giúp người khiếm thị dễ dàng tiếp cận thông tin.
● Hệ thống thông báo tự động: TTS giúp bệnh viện và phòng khám gửi thông báo về lịch hẹn, kết quả xét nghiệm hoặc hướng dẫn chăm sóc sức khỏe một cách nhanh chóng và chính xác.
● Phá vỡ rào cản ngôn ngữ: TTS có khả năng hỗ trợ nhiều ngôn ngữ, giúp bệnh nhân nước ngoài hiểu rõ hơn về tình trạng sức khỏe và hướng dẫn điều trị.

TTS giúp bệnh nhân hiểu rõ hơn về tình trạng sức khỏe
Cuộc sống hàng ngày
TTS đã trở thành một phần không thể thiếu trong các thiết bị và ứng dụng hàng ngày:
● Nhà thông minh: Công nghệ TTS được tích hợp vào các thiết bị nhà thông minh như loa thông minh, điều khiển giọng nói để đọc thông báo, nhắc nhở hoặc cung cấp thông tin thời tiết.
● Trợ lý ảo: Các trợ lý ảo như Siri, Google Assistant hoặc Alexa sử dụng TTS để trả lời câu hỏi, đọc tin tức, hoặc thực hiện các tác vụ như đặt báo thức, phát nhạc.
TTS được ứng dụng trong các trợ lý ảo như Siri, Google Assistant hoặc Alexa để trả lời câu hỏi
Giải trí và truyền thông
TTS mang đến những cải tiến đáng kể trong ngành giải trí và truyền thông:
● Lồng tiếng: Công nghệ này được sử dụng để lồng tiếng cho video hoặc phim với nhiều ngôn ngữ, giúp tiết kiệm thời gian và chi phí sản xuất.
● Tạo nội dung số: TTS hỗ trợ các nhà sáng tạo nội dung trên nền tảng số tạo ra các video hướng dẫn, tin tức hoặc quảng cáo với giọng đọc tự nhiên và thu hút.

TTS hỗ trợ nhà sáng tạo nội dung tạo ra các video hướng dẫn, tin tức hoặc quảng cáo thu hút khách hàng
Kết: Công nghệ chuyển văn bản thành giọng nói (Text to Speech) đã trải qua một hành trình phát triển dài từ những nền tảng sơ khai đến những ứng dụng hiện đại ngày nay. Hy vọng bài viết đã giúp bạn hiểu rõ hơn về lịch sử phát triển của công nghệ chuyển văn bản thành giọng nói. Nếu bạn đang tìm kiếm một ứng dụng TTS chất lượng cao, hãy tham khảo ngay ứng dụng Text to Speech của Viettel AI. Ứng dụng kết hợp với công nghệ tiên tiến, đáp ứng và hỗ trợ đắc lực nhu cầu linh hoạt của người dùng. Liên hệ đến Viettel AI ngay theo thông tin dưới đây:
Thông tin liên hệ:
● Hotline: +84 98 1900 911
● Email: viettelai@viettel.com.vn
● Địa chỉ:
○ Hà Nội: Tòa nhà Bộ Kế hoạch và Đầu tư – Số 7 Đường Tôn Thất Thuyết, Khu đô thị mới Quận Cầu Giấy, Hà Nội
○ HCM: Tầng 23, Tòa nhà Viettel Complex, 285 Cách Mạng Tháng Tám, Phường 12, Quận 10, TP. Hồ Chí Minh
● Website: https://viettelai.vn/
Bài viết khác















 Hotline: +84 98 1900 911
Hotline: +84 98 1900 911
 Email: viettelai@viettel.com.vn
Email: viettelai@viettel.com.vn
 Hà Nội: Tòa nhà Lô D25, Ngõ 7 Tôn Thất Thuyết, Phường Cầu Giấy, Hà Nội.
Hà Nội: Tòa nhà Lô D25, Ngõ 7 Tôn Thất Thuyết, Phường Cầu Giấy, Hà Nội.
HCM: Tầng 23, Tòa nhà Viettel Complex, 285 Cách Mạng Tháng Tám, phường Hòa Hưng, TPHCM.