Đã bao giờ bạn thắc mắc tại sao các công cụ trí tuệ nhân tạo (AI) như ChatGPT hay Gemini có khả năng viết một email chuyên nghiệp, tóm tắt một bản báo cáo dài cả ngàn từ hay thậm chí sáng tạo nên mã lập trình chỉ trong vài giây sau câu lệnh của bạn? Khả năng vượt trội này có được nhờ ứng dụng công nghệ cốt lõi mang tên Mô hình Ngôn ngữ lớn (Large Language Model - LLM).
Sự phát triển của LLM diễn ra với tốc độ nhanh chóng trên phạm vi toàn cầu. Theo báo cáo của Grand View Research, thị trường LLM toàn cầu được dự báo đạt khoảng 35.43 tỷ USD vào năm 2030, với tốc độ tăng trưởng CAGR khoảng 36.9% từ 2025 - 2030, thể hiện mức đầu tư và quy mô “khủng”. Đối với các doanh nghiệp lớn (Fortune 500), tỷ lệ sử dụng Gen AI dựa trên LLM khoảng 92% (theo PowerDrill AI), cho thấy LLM không chỉ ở mức “hứa hẹn” mà đã được sử dụng rộng rãi và có tác động rõ ràng.
Vậy chính xác LLM là gì, khả năng của nó đến từ đâu? Cơ chế hoạt động của nó như thế nào để có thể hiểu và trả lời ngôn ngữ của con người? Những ứng dụng thực tiễn của LLM là gì và chúng đang định hình tương lai số ra sao? Cùng tìm kiếm câu trả lời với bài viết dưới đây cùng Viettel AI.
LLM là gì? Khái niệm và cơ chế hoạt động cốt lõi
Mô hình ngôn ngữ lớn (Large Language Model – LLM) là một loại mô hình trí tuệ nhân tạo được thiết kế để xử lý, hiểu và sinh ra ngôn ngữ tự nhiên của con người. Điểm đặc trưng của LLM nằm ở quy mô cực lớn: mô hình được huấn luyện trên khối lượng dữ liệu văn bản khổng lồ (hàng trăm tỷ đến hàng nghìn tỷ từ) và sở hữu số lượng tham số rất lớn, có thể lên tới hàng chục hoặc hàng trăm tỷ tham số.
Về bản chất, LLM không “hiểu” ngôn ngữ theo cách con người suy nghĩ, mà học các quy luật thống kê và mối quan hệ ngữ cảnh giữa các từ, cụm từ và câu. Thông qua quá trình huấn luyện, mô hình dần nắm bắt được cách ngôn ngữ vận hành: từ ngữ pháp, ngữ nghĩa, sắc thái biểu đạt cho đến phong cách viết trong từng bối cảnh khác nhau.
Điều này cho phép LLM thực hiện nhiều tác vụ ngôn ngữ phức tạp như trả lời câu hỏi, viết nội dung, dịch thuật, tóm tắt văn bản, phân tích tài liệu hay hỗ trợ lập trình – tất cả chỉ dựa trên câu lệnh (prompt) của người dùng.
LLM và Generative AI
Trong hệ sinh thái trí tuệ nhân tạo hiện nay, LLM được xem là trái tim của Generative AI đối với lĩnh vực ngôn ngữ. Generative AI là nhóm công nghệ cho phép máy móc tạo ra nội dung mới (văn bản, hình ảnh, âm thanh, video, mã nguồn…) thay vì chỉ phân tích hay phân loại dữ liệu như các mô hình AI truyền thống.

Nếu Generative AI là “khả năng sáng tạo”, thì LLM chính là động cơ ngôn ngữ đứng sau khả năng đó. Nhờ LLM, các hệ thống AI có thể:
- Viết văn bản mạch lạc, logic và phù hợp ngữ cảnh
- Điều chỉnh giọng văn theo yêu cầu (trang trọng, học thuật, sáng tạo, thân thiện…)
- Phản hồi linh hoạt với nhiều loại câu hỏi, từ đơn giản đến phức tạp
Chính vì vậy, khi nói đến chatbot AI, trợ lý ảo, công cụ hỗ trợ tri thức hay hệ thống hỏi – đáp thông minh, LLM gần như luôn là thành phần trung tâm.
Kiến trúc công nghệ lõi đứng sau LLM
Đằng sau khả năng xử lý ngôn ngữ linh hoạt của các mô hình ngôn ngữ lớn là một nền tảng công nghệ được thiết kế tinh vi, trong đó kiến trúc Transformer đóng vai trò trung tâm.
Transformer là kiến trúc mạng nơ-ron được giới thiệu lần đầu vào năm 2017 và nhanh chóng trở thành tiêu chuẩn trong xử lý ngôn ngữ tự nhiên. Điểm đột phá lớn nhất của Transformer nằm ở cơ chế tự tập trung (self-attention) – cho phép mô hình xem xét mối quan hệ giữa các từ trong một câu hoặc đoạn văn một cách toàn cục, thay vì xử lý tuần tự từng từ như các kiến trúc trước đó.
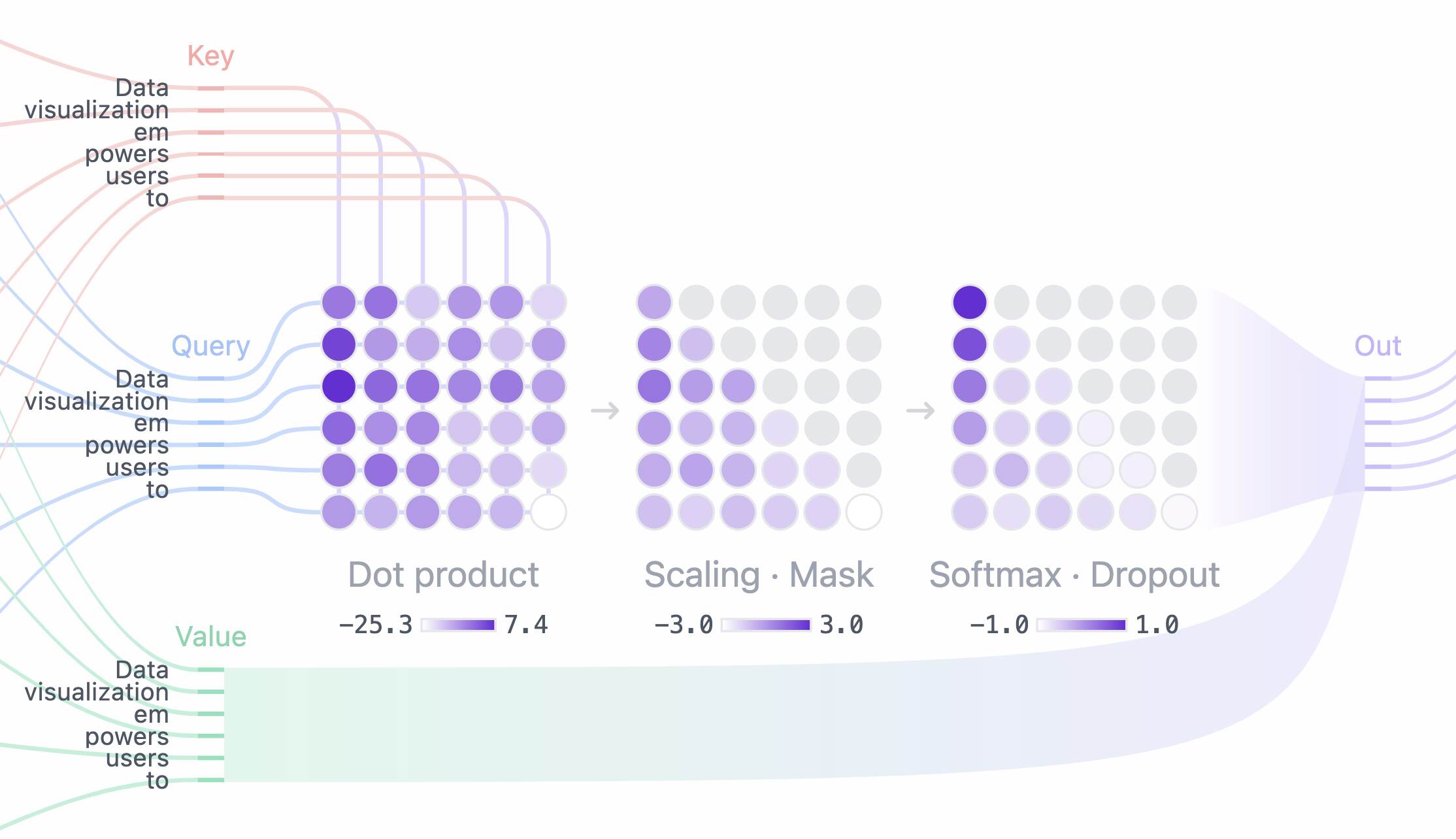
Trong ngôn ngữ tự nhiên, ý nghĩa của một từ thường phụ thuộc mạnh vào ngữ cảnh. Ví dụ, cùng một từ nhưng có thể mang ý nghĩa khác nhau tùy vào các từ xung quanh. Cơ chế self-attention giúp mô hình “chú ý” đến những từ quan trọng nhất trong câu khi xử lý một từ cụ thể, từ đó hiểu được mối liên hệ ngữ nghĩa sâu hơn.
Cụ thể, khi một câu được đưa vào mô hình, mỗi từ sẽ được ánh xạ thành các vector biểu diễn. Cơ chế self-attention sẽ tính toán mức độ liên quan giữa từng cặp từ trong câu, sau đó gán trọng số (attention weight) cho các mối quan hệ này. Nhờ vậy, mô hình có thể:
- Hiểu được ngữ cảnh dài và phức tạp
- Nắm bắt quan hệ ngữ pháp, ngữ nghĩa dù các từ ở xa nhau
- Xử lý song song toàn bộ chuỗi văn bản, giúp tăng tốc độ huấn luyện và suy luận
Một đặc điểm quan trọng khác là multi-head attention, trong đó mô hình sử dụng nhiều “đầu chú ý” song song. Mỗi head tập trung vào một khía cạnh khác nhau của ngữ cảnh (ví dụ: quan hệ ngữ pháp, ngữ nghĩa, hoặc sắc thái biểu đạt), giúp mô hình có cái nhìn đa chiều về ngôn ngữ.
Chính nhờ self-attention, LLM có thể hiểu và tạo ra những đoạn văn dài, mạch lạc, có logic – điều mà các mô hình thế hệ cũ rất khó đạt được.
Dựa trên cách tổ chức các khối Transformer, các mô hình ngôn ngữ lớn hiện nay có thể được phân thành ba nhóm kiến trúc chính: encoder-only, encoder–decoder và decoder-only. Mỗi loại có thế mạnh và mục đích sử dụng khác nhau.
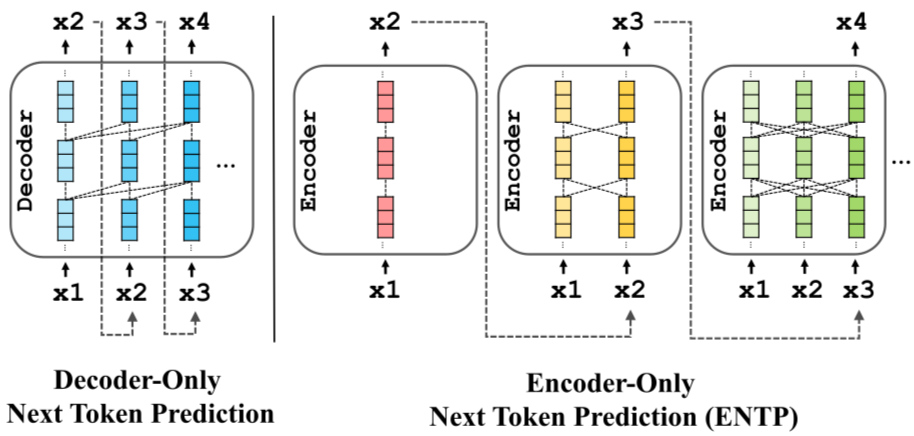
- Encoder-only: Tập trung vào hiểu ngôn ngữ
Các mô hình encoder-only được thiết kế để hiểu và biểu diễn ngôn ngữ, thay vì sinh ra văn bản dài. Encoder có khả năng phân tích toàn bộ câu hoặc đoạn văn cùng lúc, tận dụng self-attention hai chiều để nắm bắt ngữ cảnh đầy đủ.
Loại kiến trúc này đặc biệt phù hợp cho các tác vụ như phân loại văn bản, phân tích cảm xúc, trích xuất thông tin, tìm kiếm ngữ nghĩa hoặc trả lời câu hỏi dựa trên đoạn văn cho trước. Tuy nhiên, do không tối ưu cho việc sinh văn bản liên tục, encoder-only thường không được dùng làm chatbot hội thoại dài.
- Encoder–Decoder: Hiểu và sinh ngôn ngữ có cấu trúc
Kiến trúc encoder–decoder kết hợp hai thành phần: encoder để hiểu đầu vào và decoder để sinh ra đầu ra. Encoder xử lý và mã hóa thông tin từ văn bản nguồn, sau đó decoder dựa trên biểu diễn này để tạo ra văn bản mới.
Cách tiếp cận này rất hiệu quả cho các bài toán chuyển đổi ngôn ngữ, chẳng hạn như dịch máy, tóm tắt văn bản hoặc chuyển đổi định dạng nội dung. Nhờ có sự phân tách rõ ràng giữa “hiểu” và “sinh”, encoder–decoder giúp mô hình kiểm soát tốt hơn chất lượng đầu ra trong các tác vụ có cấu trúc.
- Decoder-only: Nền tảng của LLM hội thoại hiện đại
Phần lớn các LLM nổi tiếng hiện nay, đặc biệt là các mô hình hội thoại và tạo nội dung, đều sử dụng kiến trúc decoder-only. Khác với encoder-only, decoder-only được thiết kế để dự đoán từ tiếp theo dựa trên toàn bộ chuỗi trước đó, với cơ chế attention một chiều (chỉ nhìn về quá khứ).
Bên cạnh đó, một trong những yếu tố quyết định sức mạnh của LLM là số lượng tham số. Tham số có thể hiểu đơn giản là các trọng số trong mạng nơ-ron mà mô hình học được trong quá trình huấn luyện. Mỗi tham số đóng vai trò điều chỉnh cách mô hình xử lý và kết nối thông tin.
Quy mô mô hình càng lớn, số tham số càng nhiều, thì khả năng biểu diễn ngôn ngữ và nắm bắt tri thức càng cao. Với số lượng tham số lớn, LLM có thể:
- Học được các mẫu ngôn ngữ phức tạp hơn
- Ghi nhớ và tổng hợp lượng kiến thức rộng hơn
- Thực hiện nhiều nhiệm vụ khác nhau mà không cần huấn luyện lại từ đầu
Tuy nhiên, quy mô lớn cũng đi kèm với chi phí cao. Việc huấn luyện một LLM hàng chục hoặc hàng trăm tỷ tham số đòi hỏi hạ tầng tính toán mạnh, tiêu tốn nhiều năng lượng và tài nguyên. Do đó, xu hướng hiện nay không chỉ là “lớn hơn”, mà là tối ưu hơn: đạt hiệu năng cao với số tham số hợp lý, phù hợp với từng ngôn ngữ và bối cảnh sử dụng.
Đối với các quốc gia và tổ chức phát triển LLM riêng, bài toán đặt ra không chỉ là chạy đua về quy mô, mà còn là xây dựng các mô hình hiểu sâu ngôn ngữ bản địa, có hiệu quả kinh tế và khả năng triển khai thực tế.
Quy trình huấn luyện và tinh chỉnh một mô hình LLM
Để một mô hình ngôn ngữ lớn có thể hiểu, trả lời và tương tác hiệu quả với con người, nó không chỉ cần kiến trúc phù hợp mà còn phải trải qua quy trình huấn luyện và tinh chỉnh nhiều giai đoạn, với mức độ phức tạp rất cao.

Giai đoạn Đào tạo trước (Pre-training) với dữ liệu tự giám sát
Pre-training là giai đoạn nền tảng, nơi mô hình học cách ngôn ngữ vận hành ở quy mô lớn. Trong giai đoạn này, LLM được huấn luyện trên khối lượng dữ liệu văn bản khổng lồ, có thể lên tới hàng nghìn tỷ token, bao phủ nhiều chủ đề, phong cách và lĩnh vực khác nhau như tin tức, sách, tài liệu học thuật, mã nguồn và nội dung web công khai.
Điểm đặc biệt của pre-training là phương pháp tự giám sát (self-supervised learning). Thay vì cần dữ liệu được con người gán nhãn thủ công, mô hình tự tạo “nhãn” từ chính dữ liệu đầu vào. Nhiệm vụ phổ biến nhất là dự đoán token tiếp theo trong một chuỗi văn bản. Bằng cách lặp đi lặp lại nhiệm vụ này trên tập dữ liệu khổng lồ, mô hình dần học được:
- Cấu trúc ngữ pháp và quy tắc ngôn ngữ
- Mối quan hệ ngữ nghĩa giữa các từ và câu
- Kiến thức tổng quát phản ánh từ dữ liệu huấn luyện
Ở giai đoạn này, LLM chưa “biết trả lời” người dùng theo cách thân thiện hay đúng mục tiêu. Nó giống như một người đọc rất nhiều sách, có kiến thức rộng nhưng chưa được dạy cách giao tiếp hoặc làm việc theo yêu cầu cụ thể. Pre-training giúp mô hình có nền tảng ngôn ngữ và tri thức tổng quát, nhưng chưa đủ để đưa vào sử dụng trực tiếp.
Giai đoạn Tinh chỉnh bằng hướng dẫn (Instruction tuning)
Sau khi đã có nền tảng ngôn ngữ vững chắc, mô hình sẽ được đưa vào giai đoạn instruction tuning – bước chuyển quan trọng để biến LLM thành một hệ thống có thể tương tác hiệu quả với con người.
Trong giai đoạn này, mô hình được huấn luyện trên các tập dữ liệu câu lệnh – phản hồi (instruction–response), trong đó mỗi mẫu dữ liệu mô phỏng một yêu cầu cụ thể của người dùng và câu trả lời mong muốn. Ví dụ, câu lệnh có thể là “Tóm tắt đoạn văn sau”, “Viết email theo giọng trang trọng” hoặc “Giải thích khái niệm này cho người không chuyên”.
Instruction tuning giúp mô hình:
- Hiểu cách diễn đạt yêu cầu của con người
- Phân biệt các loại nhiệm vụ khác nhau
- Điều chỉnh phong cách và cấu trúc câu trả lời phù hợp với ngữ cảnh
Khác với pre-training vốn tập trung vào dự đoán token, instruction tuning hướng mô hình đến hành vi phục vụ mục tiêu, tức là trả lời đúng, rõ ràng và có ích cho người dùng. Sau giai đoạn này, LLM bắt đầu thể hiện rõ khả năng “làm theo hướng dẫn”, một yếu tố then chốt của các chatbot và trợ lý AI hiện đại.
Tối ưu hóa bằng phản hồi con người (RLHF - Reinforcement Learning from Human Feedback)
Mặc dù instruction tuning giúp mô hình hiểu yêu cầu, nhưng vẫn chưa đủ để đảm bảo rằng câu trả lời luôn phù hợp, an toàn và đúng kỳ vọng của con người. Đây là lý do RLHF – Reinforcement Learning from Human Feedback được áp dụng như một bước tinh chỉnh nâng cao.
RLHF là phương pháp kết hợp học tăng cường với phản hồi trực tiếp từ con người. Quy trình thường bao gồm ba bước chính. Trước hết, con người sẽ đánh giá hoặc xếp hạng nhiều câu trả lời khác nhau của mô hình cho cùng một câu lệnh. Từ đó, một mô hình phần thưởng (reward model) được huấn luyện để học cách đánh giá chất lượng câu trả lời dựa trên các tiêu chí như độ chính xác, tính hữu ích, mức độ an toàn và phong cách.
Sau khi có reward model, LLM sẽ được tối ưu hóa bằng thuật toán học tăng cường, trong đó mục tiêu của mô hình là tạo ra các câu trả lời có điểm phần thưởng cao nhất theo đánh giá của con người. Thông qua quá trình lặp lại này, hành vi của mô hình dần được điều chỉnh để:
- Ưu tiên câu trả lời rõ ràng, hữu ích và dễ hiểu
- Tránh nội dung gây hại, sai lệch hoặc không phù hợp
- Phản hồi nhất quán hơn với các chuẩn mực xã hội và đạo đức
RLHF đóng vai trò then chốt trong việc đưa LLM từ một mô hình “thông minh về mặt ngôn ngữ” trở thành một hệ thống đáng tin cậy để tương tác với con người. Đây cũng là lý do vì sao các LLM hiện đại ngày càng thân thiện, kiểm soát tốt hơn rủi ro và phù hợp để triển khai trong môi trường doanh nghiệp và dịch vụ công.
Ứng dụng thực tế và giá trị của LLM trong kỷ nguyên AI
LLM ngày càng chứng minh giá trị rõ ràng trong thực tiễn. Không chỉ dừng lại ở việc “trả lời câu hỏi”, mô hình ngôn ngữ lớn đang trở thành hạ tầng trí tuệ cho nhiều hệ thống số, góp phần thay đổi cách con người làm việc, khai thác tri thức và tương tác với công nghệ.

Sáng tạo và tự động hóa nội dung
LLM mang lại bước tiến lớn trong việc sáng tạo và tự động hóa nội dung khi có thể tạo ra văn bản, báo cáo, email, kịch bản hay mã lập trình chỉ từ mô tả bằng ngôn ngữ tự nhiên. Giá trị cốt lõi của LLM không chỉ nằm ở tốc độ, mà ở khả năng chuẩn hóa phong cách, duy trì tính nhất quán và hỗ trợ con người xử lý các tác vụ lặp lại, từ đó giúp đội ngũ tập trung vào các công việc mang tính chiến lược, sáng tạo và ra quyết định.
Khai thác dữ liệu và hỗ trợ tra cứu thông tin
Trong môi trường dữ liệu ngày càng phức tạp, LLM đóng vai trò như một lớp giao diện thông minh, cho phép người dùng khai thác và tra cứu thông tin bằng ngôn ngữ tự nhiên thay vì các công cụ truy vấn kỹ thuật. Khi được tích hợp với kho dữ liệu nội bộ, LLM có thể tóm tắt tài liệu, tổng hợp báo cáo, trả lời câu hỏi theo ngữ cảnh và hỗ trợ phân tích, giúp rút ngắn khoảng cách giữa dữ liệu và tri thức phục vụ công việc.
Cải thiện giao tiếp và chất lượng chăm sóc dịch vụ khách hàng
LLM giúp nâng cấp các hệ thống chatbot và trợ lý hội thoại từ mô hình kịch bản cứng sang giao tiếp linh hoạt, hiểu ngữ cảnh và ý định thực sự của người dùng. Nhờ khả năng phản hồi tự nhiên và nhất quán, LLM góp phần nâng cao tỷ lệ xử lý yêu cầu ngay từ lần tương tác đầu tiên, giảm tải cho nhân sự hỗ trợ và cải thiện trải nghiệm khách hàng trên các kênh số.
Ứng dụng LLM tiếng Việt để bản địa hóa ngữ cảnh và văn hóa
Các LLM tiếng Việt và hệ sinh thái AI bản địa ngày càng đóng vai trò quan trọng. Việc phát triển mô hình hiểu tiếng Việt không chỉ dừng ở mức dịch thuật, mà còn bao gồm khả năng nắm bắt ngữ cảnh hành chính, văn hóa giao tiếp, thói quen sử dụng ngôn ngữ của người Việt trong các lĩnh vực như dịch vụ công, tài chính, viễn thông hay giáo dục.
Trong bối cảnh đó, các sản phẩm Trợ lý ảo của Viettel AI được xây dựng dựa trên nền tảng LLM tiếng Việt, hướng tới mục tiêu hỗ trợ giao tiếp thông minh giữa con người và hệ thống số. Trợ lý ảo không chỉ có khả năng hiểu và trả lời tiếng Việt tự nhiên, mà còn được thiết kế để phù hợp với từng kịch bản ứng dụng cụ thể, từ chăm sóc khách hàng, hỗ trợ nội bộ doanh nghiệp cho đến dịch vụ công.
Thông qua việc kết hợp LLM với dữ liệu, quy trình và ngữ cảnh bản địa, các giải pháp này góp phần đưa AI đến gần hơn với người dùng Việt Nam, đồng thời đảm bảo tính chính xác, an toàn và hiệu quả khi triển khai trên quy mô lớn. Đây cũng là bước đi quan trọng để LLM không chỉ là công nghệ tiên tiến, mà trở thành công cụ thiết thực phục vụ chuyển đổi số quốc gia.
Kết luận
Sự phát triển mạnh mẽ của mô hình ngôn ngữ lớn đang cho thấy LLM không chỉ là một xu hướng công nghệ nhất thời, mà là nền tảng cốt lõi của kỷ nguyên AI tạo sinh. Việc hiểu rõ LLM là gì, cách chúng được xây dựng, huấn luyện và ứng dụng trong thực tiễn sẽ giúp doanh nghiệp và tổ chức chủ động hơn trong việc khai thác AI, từ nâng cao hiệu suất vận hành đến cải thiện trải nghiệm người dùng và thúc đẩy đổi mới sáng tạo.
Trong bối cảnh AI ngày càng gắn chặt với đời sống và hoạt động kinh tế – xã hội, những mô hình LLM được bản địa hóa, phù hợp với ngôn ngữ và văn hóa Việt Nam sẽ đóng vai trò then chốt trong quá trình chuyển đổi số bền vững.
Tiếp tục theo dõi Viettel AI để cập nhật những thông tin và tri thức mới về AI.
Bài viết khác















 Hotline: +84 98 1900 911
Hotline: +84 98 1900 911
 Email: viettelai@viettel.com.vn
Email: viettelai@viettel.com.vn
 Hà Nội: Tòa nhà Lô D25, Ngõ 7 Tôn Thất Thuyết, Phường Cầu Giấy, Hà Nội.
Hà Nội: Tòa nhà Lô D25, Ngõ 7 Tôn Thất Thuyết, Phường Cầu Giấy, Hà Nội.
HCM: Tầng 23, Tòa nhà Viettel Complex, 285 Cách Mạng Tháng Tám, phường Hòa Hưng, TPHCM.