Have you ever wondered why artificial intelligence (AI) tools like ChatGPT or Gemini can write a professional email, summarize a report thousands of words long, or even generate programming code just seconds after you give a prompt? This outstanding capability is made possible by a core technology known as the Large Language Model (LLM).
The development of LLMs is accelerating rapidly on a global scale. According to a report by Grand View Research, the global LLM market is projected to reach approximately USD 35.43 billion by 2030, with a compound annual growth rate (CAGR) of about 36.9% from 2025 to 2030, reflecting massive investment and scale. Among large enterprises (Fortune 500 companies), the adoption rate of LLM-based generative AI is around 92% (according to PowerDrill AI), showing that LLMs are no longer just “promising” but are already widely used with clear, tangible impact.
So what exactly is an LLM? Where do its capabilities come from? How does it work to understand and respond to human language? What are the real-world applications of LLMs, and how are they shaping the digital future? Let’s explore these questions together in the article below with Viettel AI.
What Is an LLM? Core Concepts and Working Mechanism
A Large Language Model (LLM) is a type of artificial intelligence model designed to process, understand, and generate human natural language. The defining characteristic of an LLM lies in its massive scale: it is trained on enormous volumes of text data (from hundreds of billions to trillions of words) and contains a very large number of parameters, which can reach tens or even hundreds of billions.
At its core, an LLM does not “understand” language in the same way humans do. Instead, it learns statistical patterns and contextual relationships between words, phrases, and sentences. Through training, the model gradually captures how language works—from grammar and semantics to tone, nuance, and writing style across different contexts.
This enables LLMs to perform a wide range of complex language tasks, such as answering questions, generating content, translating languages, summarizing documents, analyzing text, or assisting with programming—all based solely on user prompts.
LLMs and Generative AI
Within today’s artificial intelligence ecosystem, LLMs are considered the core engine of Generative AI for language-related tasks. Generative AI refers to a group of technologies that enable machines to create new content—such as text, images, audio, video, or source code—rather than merely analyzing or classifying data like traditional AI models.

If Generative AI represents “creative capability,” then LLMs are the language engines behind that capability. Thanks to LLMs, AI systems can:
- Write coherent, logical, and contextually appropriate text
- Adjust tone and style on demand (formal, academic, creative, friendly, etc.)
- Respond flexibly to a wide range of questions, from simple to highly complex
For this reason, when it comes to AI chatbots, virtual assistants, knowledge-support tools, or intelligent question-and-answer systems, LLMs are almost always the central component.
Core Technology Architecture Behind LLMs
Behind the flexible language-processing capabilities of large language models lies a sophisticated technological foundation, with the Transformer architecture at its core.
The Transformer is a neural network architecture first introduced in 2017 and quickly became the standard for natural language processing. Its most significant breakthrough is the self-attention mechanism, which allows the model to consider relationships between words in a sentence or a passage globally, rather than processing them sequentially word by word as in earlier architectures.
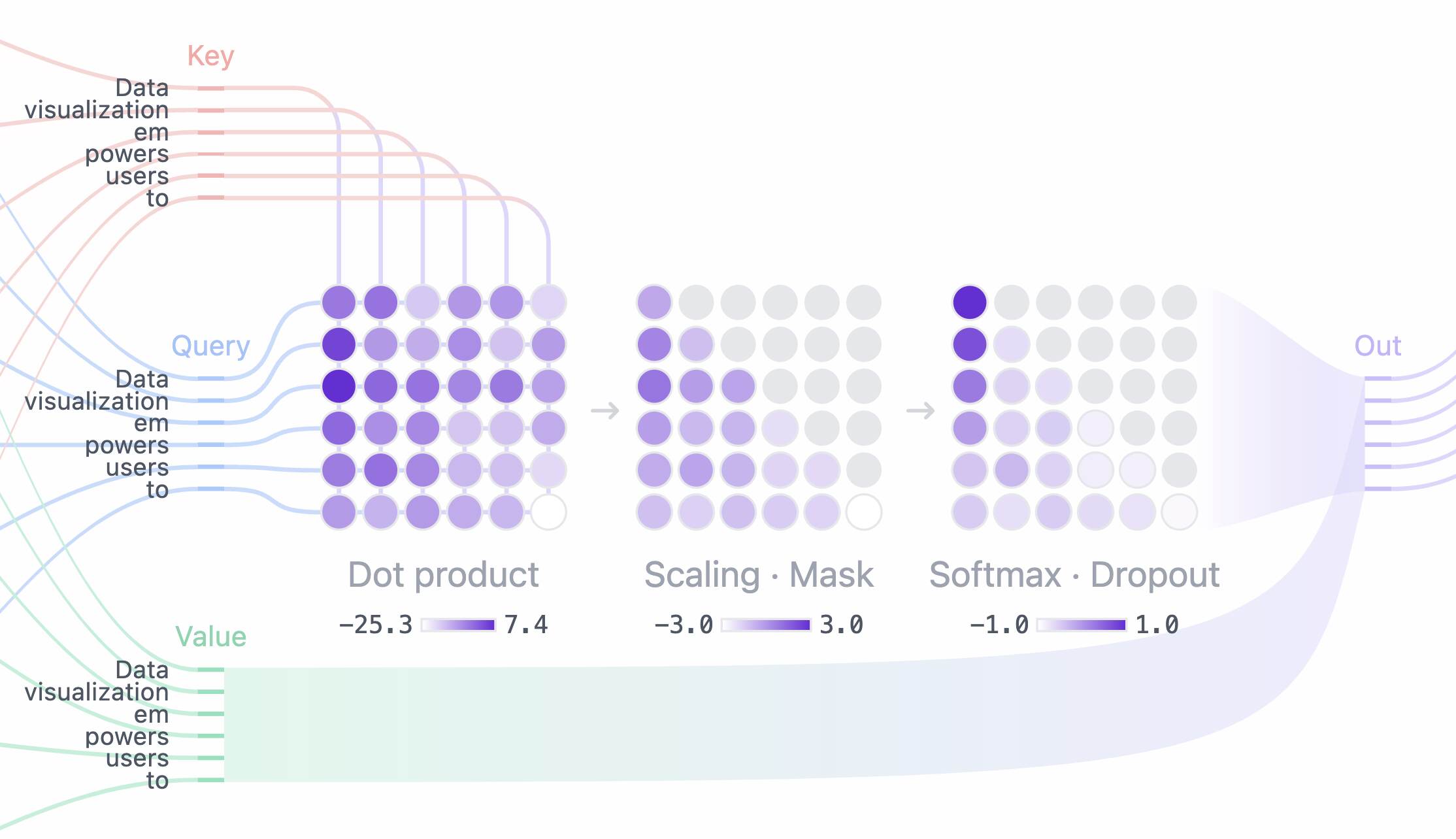
In natural language, the meaning of a word often depends heavily on context. For example, the same word can carry different meanings depending on the surrounding words. The self-attention mechanism helps the model “pay attention” to the most important words in a sentence when processing a specific word, enabling it to understand deeper semantic relationships.
Specifically, when a sentence is fed into the model, each word is mapped into a vector representation. The self-attention mechanism then calculates the degree of relevance between every pair of words in the sentence and assigns attention weights to these relationships. As a result, the model can:
- Understand long and complex contexts
- Capture grammatical and semantic relationships even when words are far apart
- Process the entire text sequence in parallel, increasing training and inference speed
Another important feature is multi-head attention, in which the model uses multiple attention “heads” in parallel. Each head focuses on a different aspect of context (for example, grammatical relationships, semantic meaning, or expressive nuance), giving the model a multidimensional view of language.
Thanks to self-attention, LLMs can understand and generate long, coherent, and logically structured passages—something that earlier-generation models found very difficult to achieve.
Based on how Transformer blocks are organized, today’s large language models can generally be classified into three main architectural groups: encoder-only, encoder–decoder, and decoder-only. Each type has its own strengths and use cases.
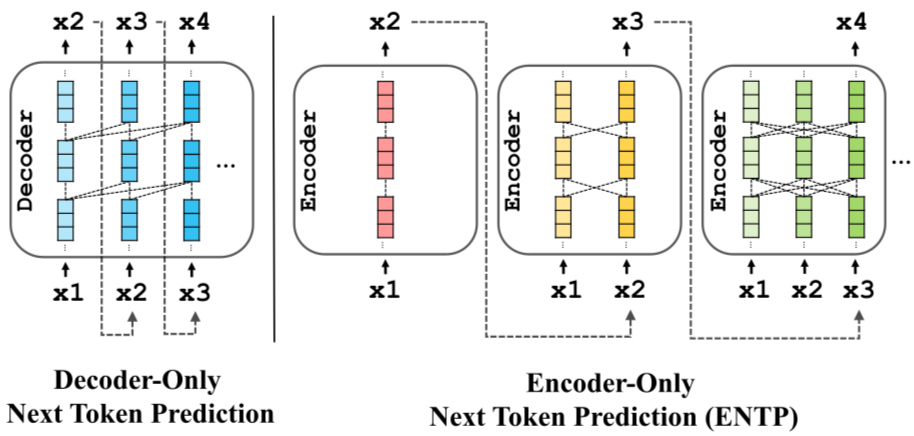
- Encoder-only: Focused on language understanding
Encoder-only models are designed to understand and represent language rather than generate long-form text. The encoder can analyze an entire sentence or passage at once, leveraging bidirectional self-attention to capture full context.
This architecture is particularly well suited for tasks such as text classification, sentiment analysis, information extraction, semantic search, or question answering based on a given passage. However, because it is not optimized for continuous text generation, encoder-only models are typically not used for long, conversational chatbots.
- Encoder–Decoder: Understanding and generating structured language
The encoder–decoder architecture combines two components: an encoder to understand the input and a decoder to generate the output. The encoder processes and encodes information from the source text, and the decoder then uses this representation to produce new text.
This approach is highly effective for language transformation tasks such as machine translation, text summarization, or content format conversion. Thanks to the clear separation between “understanding” and “generation,” encoder–decoder models offer better control over output quality in structured tasks.
- Decoder-only: The foundation of modern conversational LLMs
Most well-known LLMs today, especially conversational and content-generation models, use a decoder-only architecture. Unlike encoder-only models, decoder-only models are designed to predict the next token based on the entire preceding sequence, using a unidirectional attention mechanism that looks only at past context.
In addition, one of the key factors determining the power of an LLM is the number of parameters. Parameters can be understood simply as the weights in the neural network that the model learns during training. Each parameter plays a role in shaping how the model processes and connects information.
The larger the model and the greater the number of parameters, the stronger its ability to represent language and capture knowledge. With a large number of parameters, an LLM can:
- Learn more complex language patterns
- Store and integrate a broader range of knowledge
- Perform multiple tasks without being retrained from scratch
However, larger scale also comes with higher costs. Training an LLM with tens or hundreds of billions of parameters requires powerful computing infrastructure and consumes significant energy and resources. As a result, the current trend is not just “bigger,” but more optimized—achieving high performance with a reasonable number of parameters, tailored to specific languages and usage contexts.
For countries and organizations developing their own LLMs, the challenge is not only a race for scale, but also building models that deeply understand local languages, deliver economic efficiency, and can be deployed in real-world scenarios.
Training and fine-tuning process of an LLM
For a large language model to effectively understand, respond to, and interact with humans, it needs not only the right architecture but also to undergo a multi-stage training and fine-tuning process with a very high level of complexity.

Pre-training stage with self-supervised data
Pre-training is the foundational stage in which the model learns how language operates at scale. During this phase, an LLM is trained on an enormous volume of text data—potentially up to trillions of tokens—covering a wide range of topics, styles, and domains such as news, books, academic papers, source code, and publicly available web content.
A key characteristic of pre-training is the use of self-supervised learning. Instead of relying on human-labeled data, the model generates its own “labels” from the input data itself. The most common task is predicting the next token in a text sequence. By repeatedly performing this task across massive datasets, the model gradually learns:
- Grammatical structures and language rules
- Semantic relationships between words and sentences
- General knowledge reflected in the training data
At this stage, the LLM does not yet “know how to respond” to users in a friendly or goal-oriented way. It is like someone who has read a vast number of books and possesses broad knowledge but has not yet been taught how to communicate or work according to specific instructions. Pre-training provides the model with a strong linguistic and general knowledge foundation, but it is not sufficient for direct practical use.
Instruction tuning stage
Once the model has a solid language foundation, it moves into the instruction tuning stage—a crucial step that transforms the LLM into a system capable of interacting effectively with humans.
In this phase, the model is trained on instruction–response datasets, where each data sample simulates a specific user request and the desired response. For example, prompts may include “Summarize the following paragraph,” “Write an email in a formal tone,” or “Explain this concept to a non-expert.”
Instruction tuning enables the model to:
- Understand how humans express requests
- Distinguish between different types of tasks
- Adjust the style and structure of responses according to context
Unlike pre-training, which focuses on token prediction, instruction tuning guides the model toward goal-oriented behavior—delivering correct, clear, and useful answers to users. After this stage, the LLM begins to clearly demonstrate its ability to “follow instructions,” a key characteristic of modern AI chatbots and assistants.
Optimization through human feedback (RLHF – Reinforcement Learning from Human Feedback)
Although instruction tuning helps the model understand requests, it is still not enough to ensure that responses are always appropriate, safe, and aligned with human expectations. This is why RLHF—Reinforcement Learning from Human Feedback—is applied as an advanced fine-tuning step.
RLHF combines reinforcement learning with direct human feedback. The process typically involves three main steps. First, humans evaluate or rank multiple model-generated responses to the same prompt. Based on these evaluations, a reward model is trained to assess response quality using criteria such as accuracy, usefulness, safety, and style.
Once the reward model is in place, the LLM is optimized using reinforcement learning algorithms, with the objective of generating responses that receive the highest reward scores according to human judgment. Through this iterative process, the model’s behavior is gradually adjusted to:
- Prioritize clear, useful, and easy-to-understand responses
- Avoid harmful, misleading, or inappropriate content
- Respond more consistently with social and ethical norms
RLHF plays a critical role in transforming an LLM from a model that is merely “linguistically intelligent” into a reliable system for human interaction. This is also why modern LLMs are becoming increasingly user-friendly, better at risk control, and more suitable for deployment in enterprise and public-sector environments.
Real-world applications and value of LLMs in the AI era
LLMs are increasingly demonstrating clear value in real-world practice. Beyond simply “answering questions,” large language models are becoming an intellectual infrastructure for many digital systems, helping reshape how people work, access knowledge, and interact with technology.

Content creation and automation
LLMs bring a major breakthrough in content creation and automation by being able to generate text, reports, emails, scripts, or even source code directly from natural language descriptions. The core value of LLMs lies not only in speed, but also in their ability to standardize tone, maintain consistency, and support humans in handling repetitive tasks—allowing teams to focus on more strategic, creative, and decision-making work.
Data exploration and information retrieval support
In increasingly complex data environments, LLMs act as an intelligent interface that allows users to explore and retrieve information using natural language instead of technical query tools. When integrated with internal data repositories, LLMs can summarize documents, consolidate reports, answer context-aware questions, and support analysis—helping to bridge the gap between raw data and actionable knowledge for daily work.
Improving communication and customer service quality
LLMs upgrade chatbot and conversational assistant systems from rigid, script-based models to flexible interactions that understand user context and true intent. Thanks to their natural and consistent responses, LLMs help increase first-contact resolution rates, reduce the workload on support staff, and enhance customer experience across digital channels.
Applying Vietnamese LLMs for localization of context and culture
Vietnamese LLMs and local AI ecosystems are playing an increasingly important role. Developing models that truly understand Vietnamese goes beyond simple translation; it includes the ability to grasp administrative contexts, communication culture, and language usage habits in areas such as public services, finance, telecommunications, and education.
In this context, Viettel AI’s virtual assistants are built on Vietnamese LLM platforms, with the goal of enabling intelligent communication between humans and digital systems. These virtual assistants are not only capable of understanding and responding naturally in Vietnamese, but are also designed to fit specific application scenarios—from customer service and internal enterprise support to public-sector services.
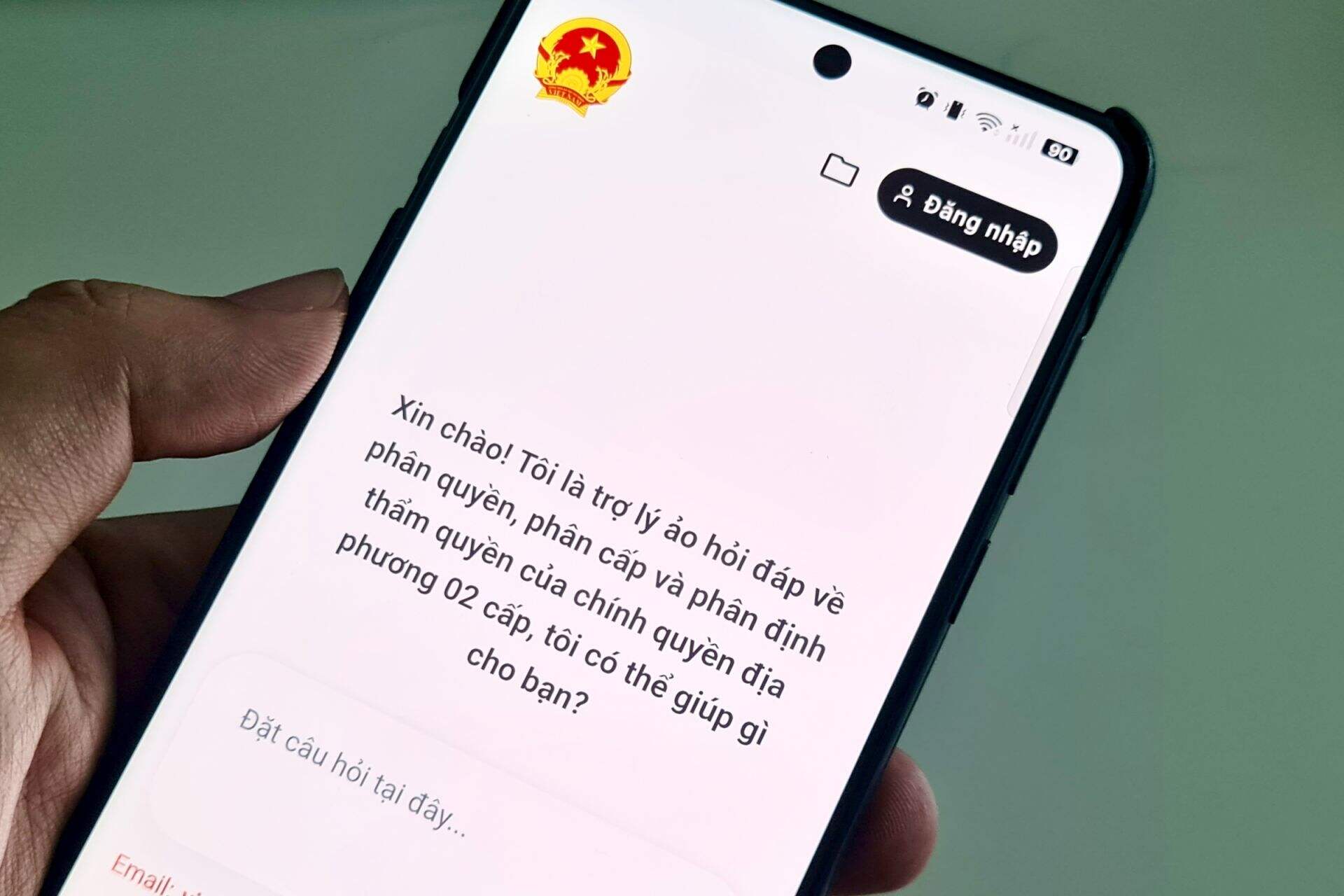
By combining LLMs with data, processes, and local context, these solutions help bring AI closer to Vietnamese users while ensuring accuracy, safety, and effectiveness when deployed at scale. This is also an important step toward ensuring that LLMs are not just advanced technologies, but practical tools that support the national digital transformation agenda.
Conclusion
The rapid development of large language models shows that LLMs are not merely a short-lived technology trend, but a core foundation of the generative AI era. Understanding what LLMs are, how they are built, trained, and applied in practice enables enterprises and organizations to take a more proactive approach to leveraging AI—from improving operational efficiency to enhancing user experience and driving innovation.
As AI becomes increasingly embedded in everyday life and socio-economic activities, localized LLMs that are well aligned with the Vietnamese language and cultural context will play a key role in achieving sustainable digital transformation.
Continue following Viettel AI to stay updated with the latest information and insights on AI.
Other news















 Hotline: +84 98 1900 911
Hotline: +84 98 1900 911
 Email: viettelai@viettel.com.vn
Email: viettelai@viettel.com.vn
 Epic Building, 19 Duy Tan Street, Cau Giay District, Hanoi.
Epic Building, 19 Duy Tan Street, Cau Giay District, Hanoi.
23rd Floor, Viettel Complex Building, 285 Cach Mang Thang Tam, Hoa Hung Ward, Ho Chi Minh City.