How Text to Speech works
Text to Speech (TTS) has made significant strides in recent years. From pairing pre-recorded audio clips to using artificial intelligence to create more natural and varied voices. This process consists of three stages, which are:
Natural Language Processing (NLP)
Natural Language Processing (NLP) is the first stage in the Text to Speech (TTS) system, which takes on the task of analyzing and preparing the input text to serve as the foundation for the next stages of processing. This process includes the following important tasks:
● Acronym expansion: To ensure that the system correctly understands the meaning of the text, TTS proceeds to expand the acronyms into the full form. For example, "BKHN" will be converted to "Hanoi Polytechnic".
● Remove special characters: Special characters such as exclamation marks, question marks, or percentage signs will be removed to clean up the text and focus on the main content.
● Standardization of reading: Numbers and language elements will be converted into a unified form. For example, the number "123" will be written as "one hundred and twenty-three" and the words will be spelled correctly and grammatically.
● Linguistic analysis: This process identifies the type of word (such as nouns, verbs) and analyzes the context to define phonemes – the smallest unit of sound, ensuring accuracy in pronunciation. In addition, the system also assigns intonation information, including elements such as emphasis, accent, or tone adjustment, making the voice more natural and easier to hear.

NLP is the first stage in the Text to Speech system
The end result of this step produces a detailed transcription, which contains full information about phonemes, accents, intonation, and breaks, ready for the next stages of processing.
Acoustic Model
After the text is processed through natural language processing (NLP) techniques, information about the language is relayed to the acoustic model. Here, this information will be transformed into the corresponding acoustic parameters. These parameters will simulate the characteristics of the human voice in detail.

The acoustic model will simulate in detail the characteristics of the human voice
Mel-Spectrogram is an important tool in acoustic modeling, used to convert audio signals into visual representations that can be processed by computers. This representation is a color map, detailing frequency bands over time. As a result, the model can analyze and extract acoustic characteristics such as pitch (related to the fundamental frequency of the sound), field (which represents the duration of the sound over time), and energy (measured in decibels).
The machine learning system processes large amounts of actual audio data to determine the link between the text and the corresponding Mel-Spectrogram representation. As a result, the system can predict how to construct a Mel-Spectrogram for any piece of text, thereby generating a synthetic voice that is not only phonetically accurate, but also emotionally rich and relevant to the communicative context.
Vocoder
Once the Mel-Spectrogram is built from the text information, it will be passed to the Vocoder model. With the support of advanced technologies such as HiFi-GAN or WaveNet, Vocoder will process this data to produce the corresponding sound. This is a key step in determining the quality of the voice, ensuring that the output sound is as realistic as the human voice. At the same time, modern Vocoder models also have the ability to fine-tune intonation, accents, as well as speed, making the voice more vivid, emotional, and suitable for each context used.
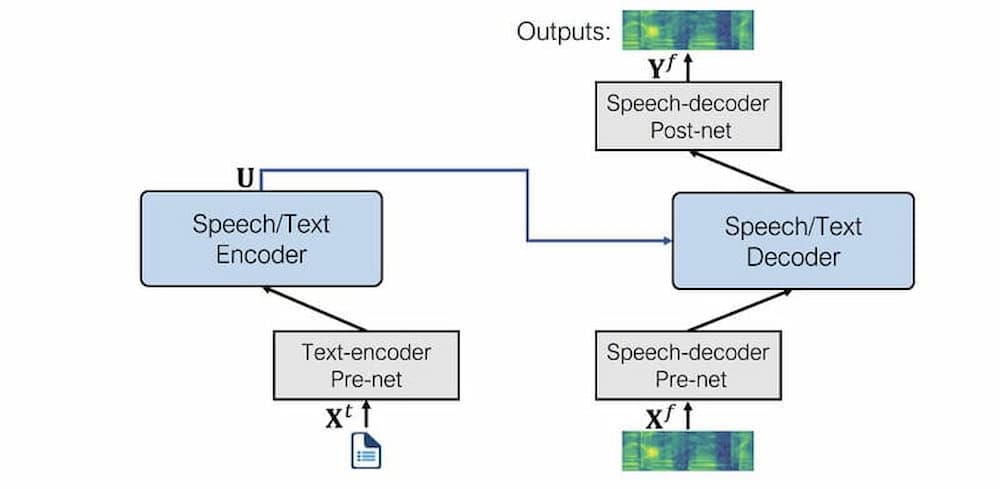
The Vocoder will process the data to produce audio with a realistic output like a human voice
The entire process from analyzing the text to generating the sound is done by deep learning algorithms, especially End-to-End models. This eliminates many intermediate steps, speeds up processing, and significantly improves the quality of the output voice. Thanks to the great advances of artificial intelligence, Text to Speech technology is becoming more and more popular and widely applied in many fields.
Application of Text to Speech technology
Text to Speech technology is changing the way we approach information. Let's find out the diverse and potential applications of this technology!
Support for the visually impaired: Text to Speech (TTS) technology is an extremely useful tool for people who are visually impaired or have limited vision. Thanks to TTS, they can access information easily, no longer depend on others.

Visually impaired people can use TTS to update information
Application in education: TTS supports the creation of audio lectures with natural voices, making it easy for learners to absorb. In addition, this technology is also integrated into online learning platforms, converting text content into speech to enhance the learning experience.

TTS supports teachers in creating immersive audio lectures
Improved user experience on mobile devices: TTS offers maximum convenience to users. Instead of having to read every word, you can listen to notifications, emails, news, and more with ease. This saves time and reduces eye strain, especially when you're working or on the go.

Users can access information easily on mobile devices
Virtual assistants and machine communication: TTS (Text to Speech) technology plays an important role in improving the interactivity of virtual assistants such as Siri, Alexa or Google Assistant. Thanks to its natural voice response, TTS makes it easy for users to communicate with the device through speech, instead of having to perform manual operations, creating a more convenient and intimate user experience.

TTS makes it easy for users to communicate with the device through speech
Control systems in smart cars: TTS is an indispensable feature in modern smart cars. Thanks to TTS, the driver can easily access information about the map, adjust the temperature, make calls or send messages without leaving the steering wheel.

TTS (Text to Speech) converts eBooks into audiobooks quickly
Application in industry and finance: This technology is used to read financial statements, update the stock market, or make announcements in business transactions, helping to save time and optimize work performance.

TTS technology is used to read financial statements accurately
Advertising and media: TTS supports the creation of professional audio commercials for radio or online content, reducing production costs but still ensuring communication efficiency.

TTS application improves communication efficiency for businesses
Medical assistance: This technology is used to read medical instructions, medical records, or pharmaceutical information, helping medical professionals and patients access information quickly and conveniently.

Ứng dụng TTS nâng cao hiệu quả truyền thông cho doanh nghiệp
Hỗ trợ trong y tế: Công nghệ này dùng để đọc các hướng dẫn y khoa, hồ sơ bệnh án, hoặc thông tin dược phẩm, giúp các chuyên gia y tế và bệnh nhân tiếp cận thông tin một cách nhanh chóng và thuận tiện.
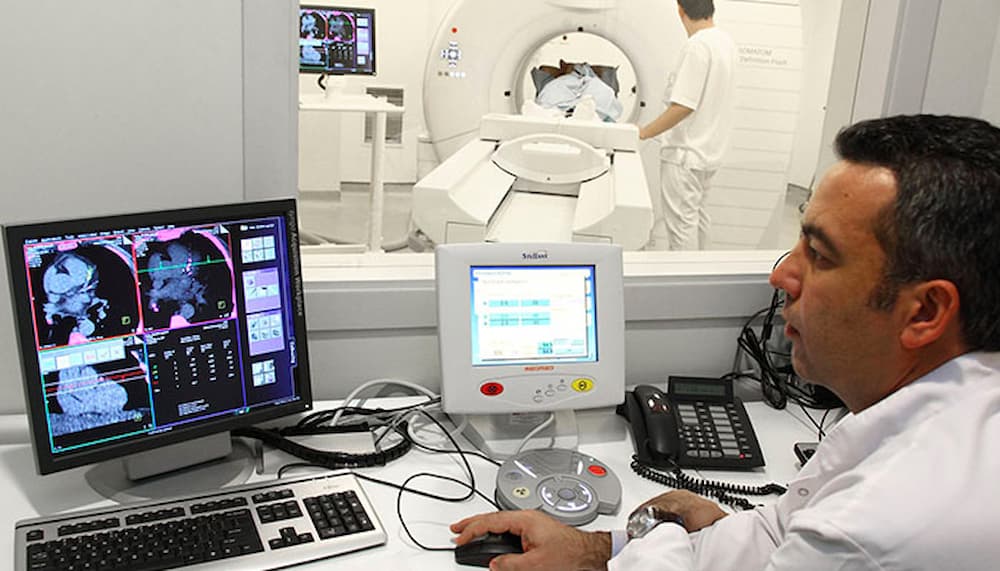
Text to Speech is used to read medical records to patients
Thus, it can be seen that TTS is not only a useful tool but also opens up great potential in many fields, contributing to improving the quality of life.
Hopefully, through this article, you have an overview of the working principle of Text to Speech technology. If you're looking for an efficient and high-quality text-to-speech solution, try Viettel AI's TTS app right away. With many superior features, Viettel TTS will be an effective companion for all your needs.
Other news















 Hotline: +84 98 1900 911
Hotline: +84 98 1900 911
 Email: viettelai@viettel.com.vn
Email: viettelai@viettel.com.vn
 D25 Building, Alley 7 Ton That Thuyet, Cau Giay Ward, Hanoi.
D25 Building, Alley 7 Ton That Thuyet, Cau Giay Ward, Hanoi.
23rd Floor, Viettel Complex Building, 285 Cach Mang Thang Tam, Hoa Hung Ward, Ho Chi Minh City.